以深度學習技術為基礎之影像處理相關研究
1.
前言
近年來神經網路深度學習技術因其強大的學習能力而被廣泛的研究與應用,巨量資料技術的發展解決了深度學習訓練時資料量不足的問題。硬體與網路技術的進步更使得深度學習訓練時間複雜度太高的難題迎刃而解,利用具深度學習功能之神經網路來進行影像處理相關研究已成為一個非常值得嘗試且可行的研究方向。
2. 應用於移動式陪伴型機器人之視覺式人體動作辨識系統之深度學習技術研發
在科技愈來愈融入生活的發展情形下,服務型機器人產品走入家庭已成為趨勢,這類服務型的機器人可在智慧家庭中扮演生活陪伴、生活協助、家庭清潔以及安全監控等角色。若要提升服務型機器人的功能,使其能在家庭中提供更多元化的服務,研發相關的智慧型軟體以提升其「智慧」程度是一個可以順勢發展且具迫切需求的課題。這類的智慧型軟體包含電腦視覺的應用領域—視覺式人體動作辨識技術。陪伴型機器人屬於服務型機器人中的一類,主要的功能為生活陪伴。生活陪伴的對象可包括家中的老人、孩童以及單獨居住的成人,目的在提升被陪伴者的居家安全感及生活品質。而視覺式人體動作辨識技術可讓陪伴型機器人適當處理攝影機的輸入訊號來「了解」人類的動作,「分析」人類的意圖,進而與被陪伴者適當的互動,以達到「生活陪伴」的目的。
目前的服務型機器人在服務使用者時,主要仍是透過語音的方式進行溝通。若是在服務使用者的同時,能夠利用攝影機取得更多的使用者資訊,例如動作、位置、移動方向等,則機器人與使用者之間的溝通能夠更加流暢且更加貼近使用者的生活習慣。因此本研究擬使用微軟的Kinect 2.0 for Xbox One深度攝影機(以下簡稱為Kinect深度攝影機)進行人體位置定位及人體動作辨識。此Kinect深度攝影機不僅擁有彩色攝影、紅外線攝影、以及深度攝影功能,且同時擁有人體骨架描繪功能。利用彩色影像、紅外線影像、深度影像、以及人體骨架資訊,互補不足之處,進而對人體動作進行更準確的辨識。
由於陪伴型機器人目前市售的價格將愈來愈親民,使得一般民眾可以負擔,因此陪伴型機器人在商業上亦有前瞻性且具研發與改良的必要性。若這些機器人的軟體「智慧」若能更進一步的提升,與被陪伴者的溝通能更良好,互動能更多元,則將使得它們陪伴的功能與效果大幅增加。而要使得被陪伴者與機器人之間有良好的溝通與互動,讓機器人能了解被陪伴者的身體語言是必要的前提。另一方面,近年來神經網路深度學習技術因其強大的學習能力而被廣泛的研究與應用,巨量資料技術的發展解決了深度學習訓練時資料量不足的問題。硬體與網路技術的進步更使得深度學習訓練時間複雜度太高的難題迎刃而解,利用具深度學習功能之神經網路來進行人體動作辨識已成為一個非常值得嘗試且可行的研究方向。因此,本實驗室擬進行應用於移動式陪伴型機器人之視覺式人體動作辨識系統之深度學習技術之研發。
(A) 研究困難
本研究將陪伴型機器人的活動範圍限定在室內,因此在執行時不考慮戶外環境導致的研究困難。不過,由於移動式陪伴型機器人的自主行動能力,故本研究需考量糸統建構在陪伴型機器人平台上所會面臨的實際的問題。也就是要解決陪伴型機器人在行動中,其攝影機所拍攝之影像可能面臨的各種狀況。如:場景的轉換、畫面的晃動、光線的差異、衣著的不同、人體外形的變化、以及視線的差異等。故將目前考慮到的研究困難列舉如下。
(1)場景轉換使得背景無法固定:隨著機器人行走動線的不同,攝影機拍攝的影像具動態的背景,使得本研究無法在背景固定的假設下,進行人體動作辨識。因此,本系統需在不建立背景影像的情形下進行前景(即被服務者)物的擷取。
(2)機器人晃動以致於畫面模糊:機器人在行走過程中因地面不平坦可能會造成震動,使得輸入影像有模糊或晃動現象,降低影像品質,提升人體動作辨識的困難度。若能採用多張的連續影像資訊,也許能克服單張影像模糊或晃動的問題。
(3)機器人相對移動速度過快導致系統處理時間太短:由於陪伴型機器人常與被服務者互動,二者的相對移動速度若太快時,系統對服務者位置及動作辨識的時間則會太短,造成機器人無法進行適當的反應。另一方面,相對速度過快亦會造成深度影像的擷取問題。
(4)光線差異影響系統穩定性:雖然影像是在室內拍攝,但戶外攝入的陽光或室內的燈具的開關皆會造成彩色影像中色彩差異,降低系統辨識時的穩定性。另外,被陪伴者在室內活動時造成的光影變化,室內電視電腦螢幕等畫面切換所導致的光線變化,也是需要考慮並解決的問題。
(5)紅外線感光問題:本計畫深度影像擬由Kinect攝影機的IR Emitters所發射的紅外線之反射取得。但是紅外線的反射強度會受物體表面的粗糙程度影響,因此,人的頭髪或衣著部份常常無法取得正確的深度值,影響由深度影像擷取出的特徵之正確性。
(6)衣著款式或顏色差異影響特徵穩定性:被陪伴者所穿著之服裝形式與色系有可能常常改變,本計畫所研發的系統需能適應這一類型的變化。另外,若被陪伴者所穿著之服裝顏色與背景顏色太過雷同,也可能會影響特徵穩定性、降低人體動作辨識之準確率,這也是一個需要克服的問題。
(7)人體形變提升辨識的困難度:人體屬於形變物體(non-rigid
object),有別於固形物體(rigid objects)的不變形體,形變物體動作偵測與辨識的困難度較高,要考慮多樣性的問題。因此,在動作特徵的選取時需要慎重考慮該特徵在物體形變時的穩定性。
(8)視角差異造成的動作差異問題:相同的動作從不同角度看,看到的動作形態有可能是不同的。本計畫期望機器人不論在何種角度,都能辨識被陪伴者的動作。因此,只建構單一面向的人體動作模型不足以滿足這種要求,要考慮更多層面的解決方案。另外,有時人體的各個部位在某些角度看來還有可能相互遮蔽,導致系統難以辨識其真正動作。
(9)人體動作的不精確性:經驗顯示即使要求同一個被陪伴者作相同的動作也並非每次都能完全相同,更何況是不同行為習慣的人作相同的動作。這是人體動作中非常明顯的不精確性,也導致人體動作辨識時很大的困難。
(10)多人在影像中可能造成相互遮蔽問題:多人同時出現在影像中有更多更複雜的遮蔽問題要考慮。另外,不同被陪伴者與機器人距離的遠近不同,他們在影像中呈現的大小亦不會相同,非常考驗所選取的特徵類型與分類系統的穩定性。
為了提升人體動作辨識系統的穩定性,排除或克服上述的研究困難是必要的。本計畫擬從動作特徵之擷取、動作分類器之選擇方面著手,逐一考慮並選擇相對較佳的作法,以期本研究最終能獲得一個較穩定的適用於陪伴型機器人的人體動作辨識技術。
(B) 人體動作分析
表一所列為本計畫參考文獻探討中大部份的人體動作資料庫後所整理之陪伴型機器人需辨識之人體動作以及可能之回應。表一中將人體動作分為單人動作與人機互動動作二類。其中第一類型的單人動作詳列被陪伴者可能之動作,包含站立、蹲下、打滾、跪坐、走路、跑步、跳、坐下、跌倒下、躺下、以及趴下等十一種動作。由於陪伴型機器人陪伴的對象包括老人和兒童,因此這些動作包括老人和兒童可能的動作。要注意的是單人動作並非指畫面中僅有一人時的動作,若畫面中有二位(含)以上的被陪伴者,也許他們有人坐下、有人站立,只是沒有互動,這些情況皆屬單人動作辨識的範圍。
表一、陪伴型機器人需辨識之人體動作以及可能之回應。
|
類型 |
編號 |
動作描述 |
狀況 |
機器人回應 |
|
單人動作 |
1 |
站立 |
被陪伴者站立於前方 |
觀察並陪伴 |
|
2 |
蹲下 |
被陪伴者蹲著 |
觀察並陪伴 |
|
|
3 |
打滾 |
被陪伴者於地上或床上打滾 |
觀察並陪伴、有狀況則發出警訊 |
|
|
4 |
跪坐 |
被陪伴者跪坐於地上或椅子上 |
觀察並陪伴 |
|
|
5 |
走路 |
被陪伴者朝機器人方向行走 被陪伴者行走於室內 |
觀察並陪伴、辨識出是否為被陪伴者 |
|
|
6 |
跑步 |
被陪伴者於室內跑步 |
觀察並陪伴、有狀況則發出警訊 |
|
|
7 |
跳 |
被陪伴者跳 |
觀察並陪伴 |
|
|
8 |
坐下 |
被陪伴者坐於地板或椅子上 |
觀察並陪伴 |
|
|
9 |
跌倒 |
被陪伴者跌倒 |
詢問並發出警訊讓他人協助 |
|
|
10 |
躺下 |
被陪伴者躺於床上或沙發 |
觀察、陪伴並偵測呼吸 |
|
|
11 |
趴下 |
被陪伴者趴在桌上或床上 |
觀察、陪伴並偵測呼吸 |
|
|
人機互動動作 |
12 |
打招呼 |
被陪伴者對機器人揮手打招呼 |
打招呼 |
|
13 |
擁抱 |
被陪伴者與機器人擁抱 |
擁抱 |
|
|
14 |
交談 |
被陪伴者與機器人交談 |
與被陪伴務者對話 |
|
|
15 |
握手 |
被陪伴者與機器人握手 |
與被陪伴者握手 |
|
|
16 |
敬禮 |
被陪伴者與機器人敬禮 |
與被陪伴者回禮 |
|
|
17 |
搭肩 |
被陪伴者與機器人搭肩 |
與被陪伴者搭肩 |
|
|
18 |
擊掌 |
被陪伴者與機器人擊掌 |
與被陪伴者擊掌 |
本系統辨識出各種動作後,將會發出訊息交由機器人作出相對的回應,如表一的最後一欄所列。大部份的回應皆為「觀察並陪伴」,但在必要時會詢問、發出警訊通知其他人並請求協助。而在人機互動的部份,機器人則會打招呼、擁抱、或與被陪伴者交談。以上這一系列的初步動作分析將隨著計畫的執行而調整與改變,以期最終能符合移動式陪伴型機器人所應具備的功能。
(C) 系統流程
本系統之主流程如圖一所示,系統首先讀入經由Kinect擷取的彩色影像、紅外線影像、深度影像、以及骨架資訊。將彩色影像與深度影像分別進行適當的前處理(pre-processing)後,再分別送入不同的神經網路進行人體動作的分類(human
action classification)。同時,人體的骨架資訊亦訓練不同的神經網路來進行分類。彩色影像中不同顏色的移動與深度影像中同一像素點深度值的變化皆可能做為人體動作分類的特徵。同理,人體的骨架中關節點的移動亦可以提供人體動作的資訊。這些輸入的訊息在某些狀況下具互補的作用。例如當人物的衣著與背景顏色相近時,深度影像也許可以提供較好的辨識特徵;而人物與其他物體位置相近時,骨架資訊就可扮演區分的角色。而在光源不足的情況下,紅外線影像將提供較穩定的特徵。因此,這些分類的結果需經由integration步驟整合後輸出最後的人體動作辨識結果。整合時需考慮各種資訊提供時的信心程度,以便達到較佳的辨識率。最後系統根據辨識的結果輸出如表一中所對應的反應。
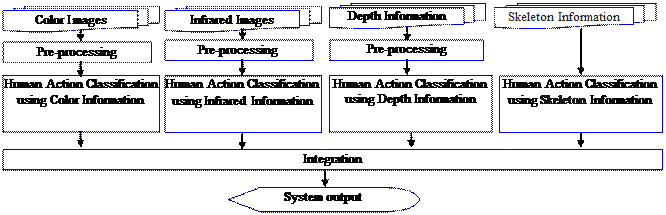
圖一、人體動作辨識系統流程圖。




(a) (b) (c)
(d)
圖二、Kinect可提供的輸入資料範例。彩色影像;(b) 紅外線影像;(c) 深度影像;(c)骨架資訊(整合於深度影像中)。
3. 以深度學習神經網路為基礎之視覺式食物熱量及營養成分量測系統之研究
在醫療進步的今天,高齡人口愈來愈多,再加上對生活品質的追求,現代人愈來愈重視身體的健康。專家建議要維持個人身體的健康,應從定期的適量運動及均衡的飲食習慣著手。由於健康生活觀念的普及與推廣,國人逐漸了解運動的重要性。但在飲食方面,大部份的國人並不清楚且不太重視各種食物的熱量與營養成份,在選擇食物時較在意個人的喜好而非均衡的營養選擇,因此本計畫擬開發一套視覺式食物熱量及營養成份量測系統,以便利、隨身的方式讓使用者能了解每日飲食的熱量與營養成份,進而達到控制飲食均衡的目的。





圖三、烹調完成的餐點照片。
本計畫之視覺式食物熱量及營養成份量測系統利用隨身手機拍攝烹調完成的餐點照片或影片,以電腦視覺與影像處理的新技術進行前處理,偵測並分辨出餐盤上的每一種食物的類別,估計它們的體積及分量,並利用已知的食物熱量表以及食品營養成份表估算其熱量與營養成份,提供使用者參考。由於食物的種類繁多,烹調的方式非常多樣化,且部份食物經切割及混合烹煮後不再具備原來的形體與色澤,因此以視覺式技術來進行食物熱量及營養成份量測有著非常高的複雜度及困難度。由於西式早餐種類較為固定、食物擺盤重疊性較低(如圖一所示),本計畫擬先針對西式早餐進行視覺式熱量與營養成份量測,未來期望能擴展至西式午餐或晚餐,甚至是中式的各種餐點。
另一方面,近來在巨量資料技術的發展與電腦高速計算能力的配合下,類神經網路深度學習功能日進千里,使得機器學習技術訓練時資料量不足以及時間複雜度太高的難題都迎刃而解。因此本計畫認為利用具深度學習功能之神經網路來進行食物偵測與食物辨識己成為一個非常值得嘗試且可行的研究方向。故本計畫擬從西式早餐的熱量與營養成份量測入手,以具深度學習功能之神經網路技術為手段,開發視覺式的食物熱量及營養成份量測系統,期能對現代人的健康盡一份心力。
(A) 研究困難
本研究將擬量測之熱量與營養成份的食物範圍限定於西式早餐,主要原因為西式早餐的種類較為固定、餐點擺放方式較為平整、食物擺放時重疊性較低,因此在現階段不考慮西式午餐或晚餐甚至是中式餐點多道菜色所需面臨的研究困難。不過,在西式早餐餐盤上進行食物的偵測與辨識,還是要考慮食物經切割及混合烹煮後一部份形體與色澤改變的問題。另外,傳統影像拍攝時的光影變化的問題亦是要考慮的因素。故將目前考慮到的研究困難列舉如下:
(1)
餐盤的形狀大小顏色與材質的多樣性問題:不同的家庭或餐廳所使用的餐盤必是不同的。各式各樣不同花色、形狀、材質、大小的餐盤必定會導致食物的偵測困難,如圖一中即有三種常用的圓形餐盤。部份研究省略餐盤的偵測步驟,直接進行食物的偵測,但此種作法亦無法處理餐盤色澤或花紋形狀近似食物所造成的干擾問題。另有部份研究假設餐盤皆為白色圓形,不過這種假設會降低系統的一般性,導致日後難以推廣。
(2)
餐桌的顏色與材質的干擾問題:放置餐盤的餐桌在大部份的情況下皆會入鏡,更何況有些食物的擺盤會超出餐盤的範圍,因此餐桌的顏色與材質可能會造成干擾亦是本研究需處理的問題之一。
(3)
光線差異影響系統穩定性:所有的影像系統都要考慮光線差異的問題,不同的使用者用不同的手機在不同的地方拍攝相同的食物,其偵測與辨識結果必需相同,才能符合系統穩定性的要求。傳統的影像前處理技術想必能在此一問題上有所貢獻。
(4) 食物經切割及混合烹煮後形體與色澤改變的問題:大部份的食物在烹煮時需要經過切割,而且二種以上的食材混合烹煮更是常見,這類食物烹煮後形體與色澤改變的問題會導致極大的偵測與辨識上的困難,且不易解決。採用類神經網路的深度學習技術也許是可能的較佳手段。
(5) 食物擺放重疊造成遮蔽問題:食物重疊擺放常造成偵測辨識困難。利用不同的角度拍攝多張照片或是拍攝環場連續影片也許可以部份解決食物擺放重疊造成的遮蔽問題。如圖十八所示,一張由上向下拍的影像加上二張側拍的影像,也許可以協助解決部份問題。
(6) 調味料或調味醬造成的干擾:沙拉醬、蕃茄醬、塔塔醬等各類調味醬,加上胡椒、鹽、糖、香料等調味料,會影響食物的顏色及外觀,亦會導致食物偵測與辨識的困難。
(7) 食物的分量在影像中沒有參照對象:相機離拍攝物的距離不固定,加上餐盤大小不一,使得食物的分量估計在影像中沒有參照對象,會導致食物熱量和營養成份的計算困難。有些研究建議使用者在拍攝照片時需包含使用者的大姆指以解決此問題。另一方面,標示旗的使用也可以解決此一問題。
(8) 食物的高度資訊難以取得:在單一影像中不易取得食物的高度資訊,較難估計食物的分量,因此易導致食物熱量和營養成份的估計誤差。利用不同的角度拍攝多張影像或是拍攝環場連續影片除了可以解決部份食物擺放重疊造成遮蔽問題,亦對食物的高度資訊取得有所助益。一張由上向下拍的影像加上二張側拍的影像,可得出厚片吐司的面積與高度,也許可以協助解決此一問題。
(9) 視角差異造成的誤差問題:大部份的使用者在拍攝照片時所採取的視角不會完全符合研究假設的標準,系統需要提供部份彈性解決這類的問題,才能避免視角差異造成的誤差。
(10) 拍攝照片或影片時的手震問題:由於本系統的設計強調隨身方便,輸入之照片或影片為使用者自行拍攝,故非常難以避免手震所造成的問題。因此處理手震所造成的影像也是本研究需考慮的解決的問題。
為了提升視覺式食物熱量及營養成份量測系統的穩定性,排除或克服上述的研究困難是必要的。本計畫擬從食物特徵之擷取、食物之偵測、食物分類器之選擇方面著手,逐一考慮並選擇相對較佳的作法,以期本研究最終能獲得一個較穩定的視覺式食物熱量及營養成份量測技術。
(B) 系統流程
本系統之主流程如圖四所示,主要分為五個主要的核心步驟,分別為影像前處理、食物之偵測、食物之辨識、食物體積估測以及食物熱量及營養成份量測。食物影像輸入系統時第一個步驟即為前處理,主要目的在過濾雜訊以及去除手震影響。影像的前處理可以提高後續食物偵測時的正確率。食物偵測步驟主要在區分影像中食物與非食物的區塊,切割出食物的區塊做為ROI(region of interest)以便進行食物辨識。食物辨識步驟在確認食物的種類,藉以取得食物熱量及營養成份資料庫中的資料以便進行熱量及營養成份估算。而食物體積估測的目的則在提升食物熱量及營養成份估算的正確性。利用食物的體積以及密度可以計算食物的重量,配合食物熱量及營養成份資料庫的查詢,可以估算輸入影像中使用者所攝取的食物熱量及營養成份。最後,系統會記錄並輸出相關數據供使用者參考。
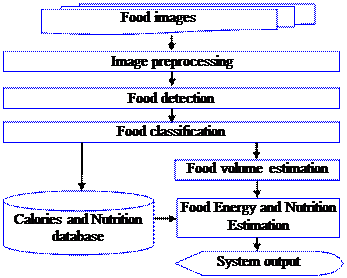
圖四、視覺式食物熱量及營養成份量測系統流程圖。